评估与测试
概述
评估与测试功能是一个专业的模型评估工具,主要用于帮助用户全面评估和比较不同模型的性能表现。该功能包含三个主要评估方式:MT-BENCH 基准测试、对抗评估和自定义评测。
登录到 AISTACK 平台,在左侧功能列中选择【评估与测试】,进入模型评估界面。您可在此处创建新的评估任务,只需选择要评估的模型服务即可自动开始评估。您可以方便地查看和比较不同模型的评估结果,为模型选择和优化提供可靠的数据支持。
核心特性
- 自动化评估:只需选择模型服务即可自动开始评估
- 多维度对比:支持多维度的性能对比分析
- 客观标准:提供客观、标准化的评估标准
MT-BENCH 基准测试
MT-BENCH 基准测试通过标准化的数据集对模型进行全面评估,衡量模型的准确性和效率,提供可靠且具有可比性的测试结果,确保评估环境的标准化。
功能特点
- 通过标准化的数据集对模型进行全面评估
- 衡量模型的准确性和效率
- 提供可靠且具有可比性的测试结果
- 确保评估环境的标准化
创建 MT-bench 评估任务
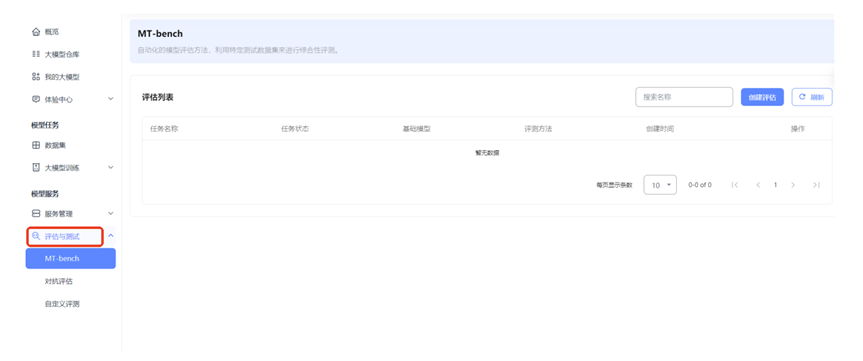
点击【创建评估】开始创建新的 MT-bench 评估任务。
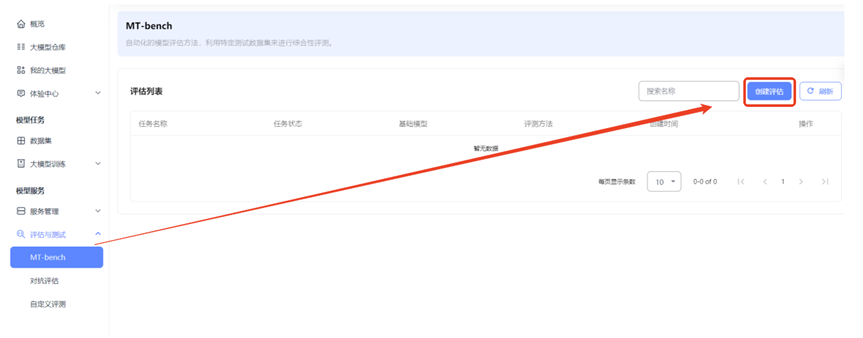
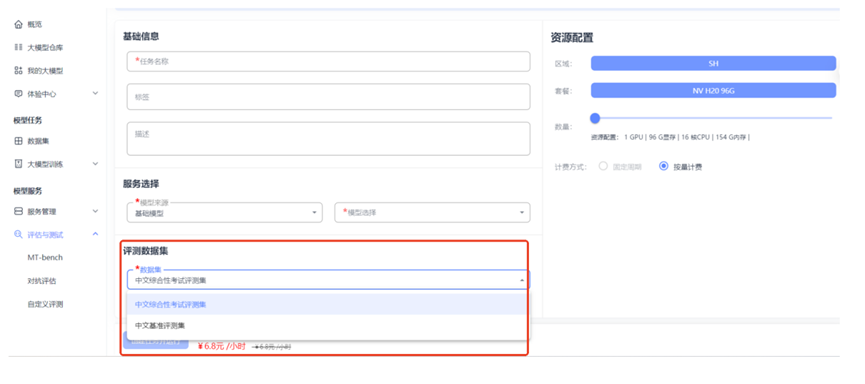
基本信息配置
填写好任务名称后,可以选择填写相应标签、描述等信息。
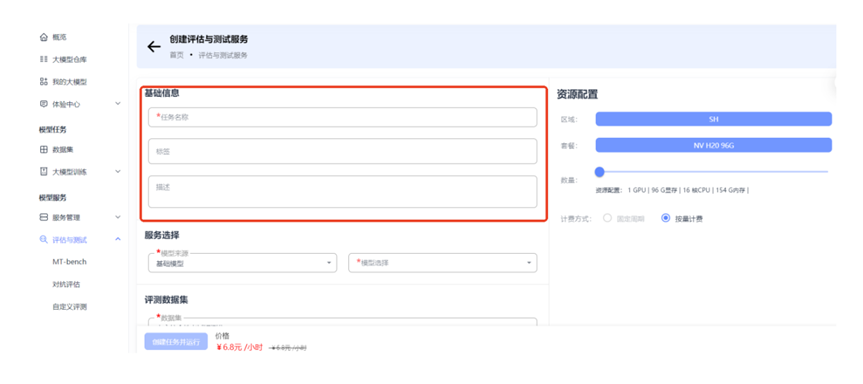
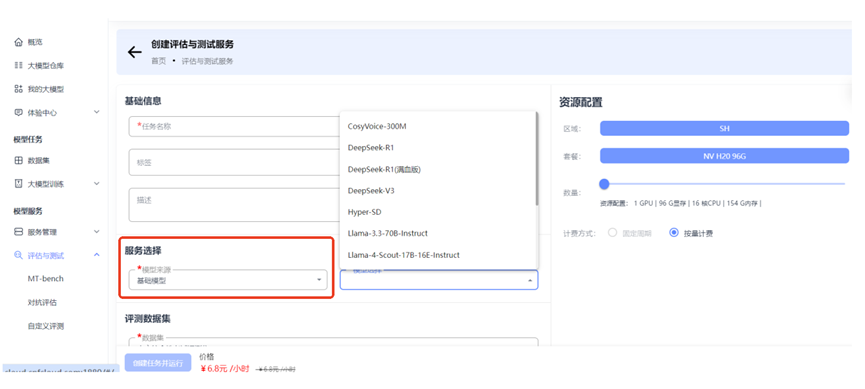
服务选择
评估的模型可以选择以下两类:
- 大模型仓库的基础模型:平台预置的原始大模型
- 我的大模型中的训练后模型:用户经过训练或微调后的模型
评测数据集
目前评测数据集提供两种较为全面的数据集:
中文综合性考试评测集
面向中文语言模型的综合性考试评测集,是目前较为权威的中文 AI 大模型评测榜。该数据集涵盖多个学科领域,能够全面评估模型在不同知识领域的表现。
中文基准评测集
用于评估语言模型在中文语境下的知识和推理能力。该数据集专注于测试模型对中文语言的理解和生成能力。
使用建议
- 评估前准备:确保要评估的模型服务处于正常运行状态
- 合理选择数据集:根据模型的应用场景选择合适的评测数据集
- 结果分析:结合多个评估维度综合分析模型性能
- 对比评估:可同时评估多个模型进行性能对比
- 持续监控:定期对模型进行评估,监控性能变化
通过系统的评估与测试,您可以:
- 客观了解模型的实际性能表现
- 为模型优化提供数据支持
- 在多个模型中做出明智选择
- 验证模型训练和微调的效果