大模型训练
概述
平台的大模型训练功能为用户提供了完整、高效、易用的模型训练工具链,支持监督学习(SFT)和强化学习(RLHF)两大主流训练方式。用户可根据实际需求,灵活选择不同的训练模式和配置,以实现个性化、高性能的模型微调。
登录到平台,在左侧功能列中选择【大模型训练】,进入训练管理界面。您可在此处创建和管理您的训练任务,支持选择基础模型、配置训练参数、上传训练数据集等操作。
平台提供了丰富的训练配置选项,包括资源分配、节点选择、评测条目等,同时支持训练过程的实时监控和管理。您可以随时查看训练进度,进行暂停、继续或停止等操作,灵活掌控整个训练流程。训练完成后的模型可直接用于部署推理服务,实现从训练到部署的无缝衔接。
监督学习训练(Supervised Fine-Tuning, SFT)
SFT 实际上是 Fine-Tuning 的训练模式,开发者可以选择适合自己任务场景的训练模式并加以调参训练,从而实现理想的模型效果。
监督学习训练适用于有明确标注数据的场景,通过对预训练大模型进行微调,使模型更精准地适应特定任务需求。
适用场景
- 文本生成(如问答对话、内容创作)
- 特定领域的知识问答(医疗、法律、金融等)
特点
- 需要明确的标注数据(Prompt-Response)
- 训练过程相对稳定,效果容易评估
- 快速提升模型在特定任务上的表现
创建任务
如果您在训练任务列表已经有创建好的训练任务,可以直接点击【复制任务】创建相同参数的训练任务。
也可以点击【创建训练任务】直接创建新任务。
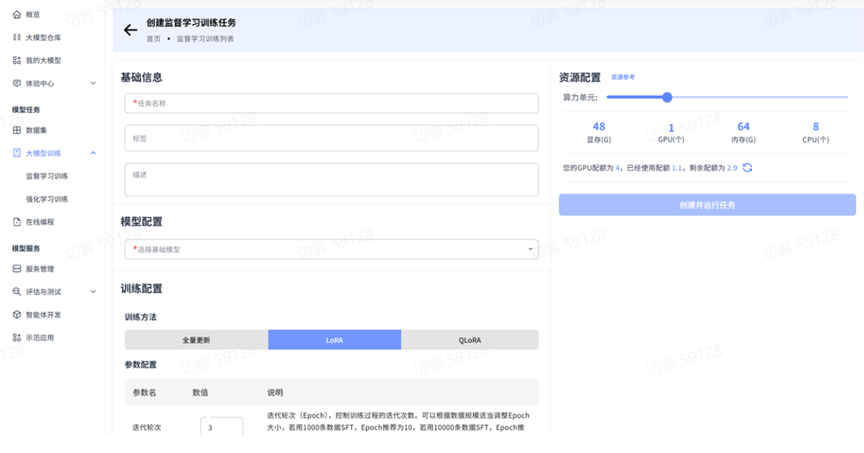
基本信息配置
填写好任务名称后,可以选择填写相应标签、描述等信息。
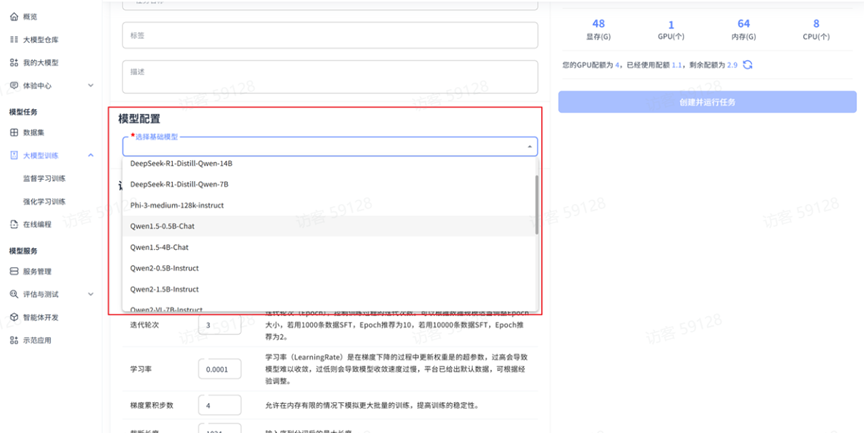
模型配置
当前 SFT 任务支持的通用模型为:非量化版本且未微调训练过的语言类模型。
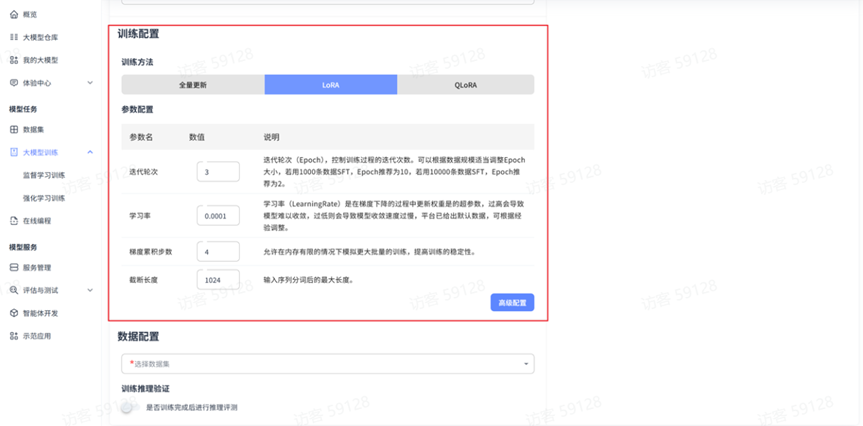
训练配置
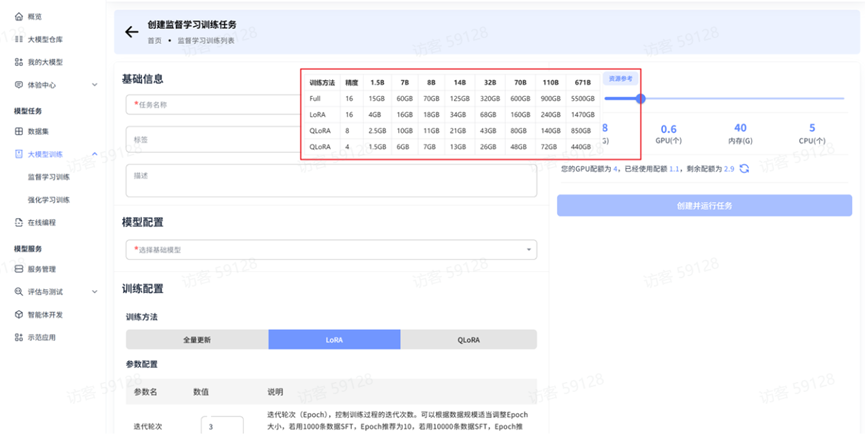
平台监督学习训练提供三种训练方法,分别是:全量更新、LoRA、QLoRA,用户可根据自身需求和资源条件选择最适合的方法。
训练方法对比
| 训练方法 | 原理 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 全量更新 | 对模型的所有参数进行更新和调整 | • 训练效果最佳 • 可深度调整模型能力 • 适合复杂任务场景 | • 计算资源需求极高 • 训练时间长成本高 • 存在灾难性遗忘风险 | 拥有充足计算资源的企业级应用 |
| LoRA | 通过低秩分解矩阵表示参数更新,只训练小矩阵 | • 大幅降低计算资源需求 • 训练速度快成本低 • 微调参数量小便于部署 | • 性能提升有一定上限 • 需合理设置参数 | 中小规模数据集的领域适应 |
| QLoRA | 在 LoRA 基础上对基础模型进行量化处理 | • 极低显存需求 • 保留 LoRA 大部分效果 • 训练成本最低 | • 量化过程可能带来性能损失 • 训练过程相对复杂 | 资源极度受限环境、个人开发者 |
参数配置
在 SFT 训练任务中,可以设置以下训练参数:
基础参数:
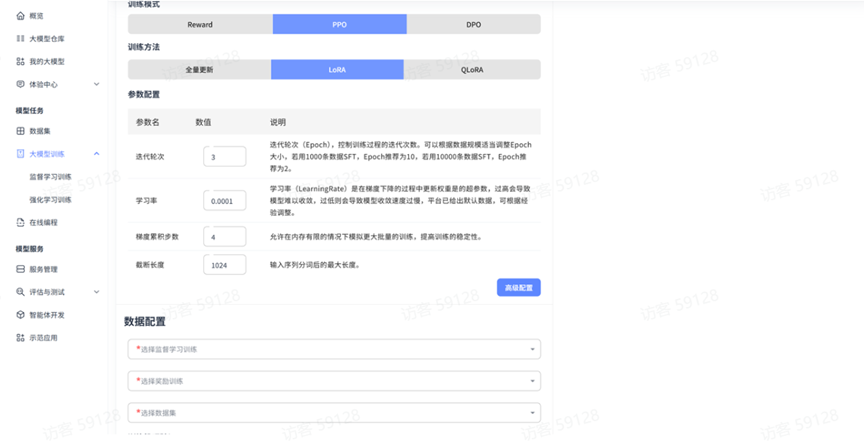
- 训练轮次(Epoch):控制训练过程的迭代次数。建议:1000 条数据推荐 10 轮,10000 条数据推荐 2 轮
- 学习率(LearningRate):更新权重的超参数,过高导致难以收敛,过低导致收敛过慢
- 梯度累计步数:在内存有限情况下模拟更大批量训练,提高稳定性
- 截断长度:输入序列分词后的最大长度
这些参数可根据具体任务需求和数据集特点进行灵活调整,以达到最佳训练效果。调参过程中建议记录不同配置下的模型表现,以便找到最优组合。
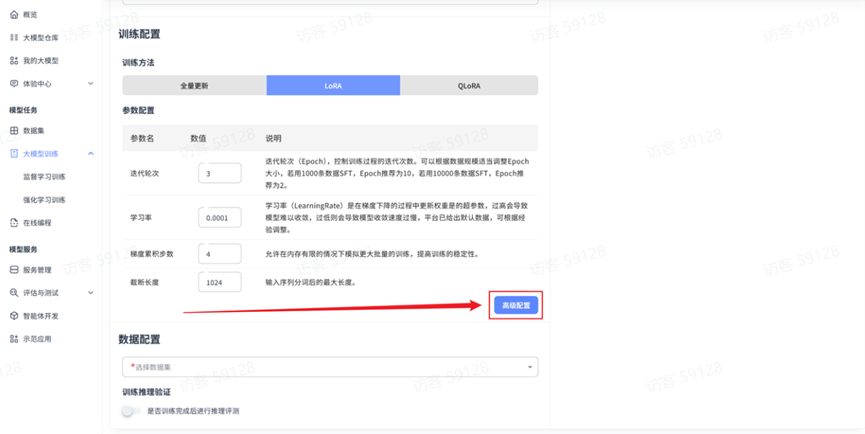
高级参数: 如需更精细的控制,还可调整高级参数,如最大样本数、批处理大小、预热步数等。
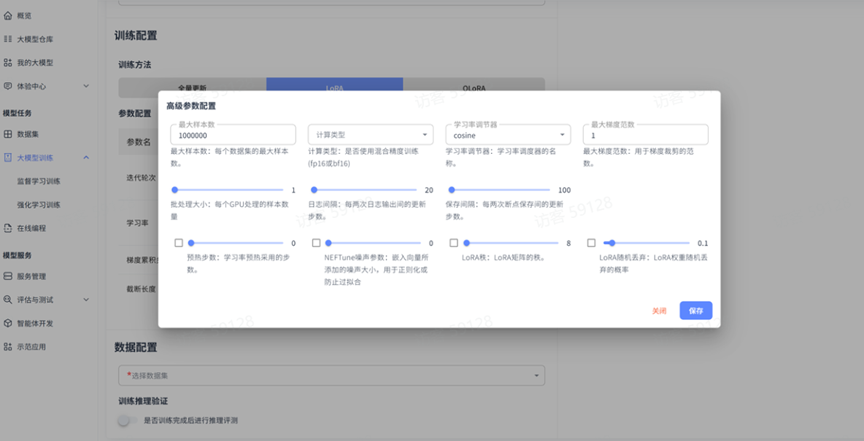
高级参数的详细解释请参考:训练参数介绍
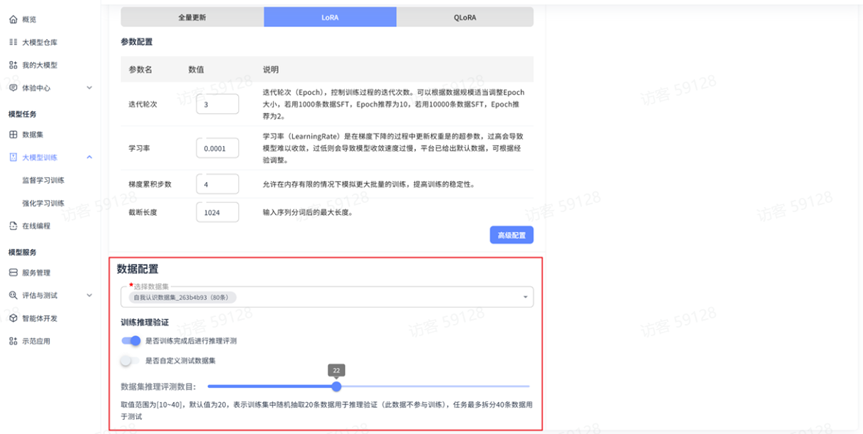
数据配置
数据配置是模型训练过程中的关键环节,允许用户灵活选择和管理训练所需的数据资源,并设置验证评估方式。
数据集选择:用户可从个人或共享数据集中选择适合当前训练任务的数据集。
训练推理验证:
- 启用验证:可选择是否在训练过程中进行实时验证评估,抽取对应数量的数据作为验证(不参与训练)
- 评测指标:可选择多种评估指标,如准确率、F1 分数、BLEU 分数、ROUGE 分数等
- 验证数据量:默认不抽取超过数据集数量一半的数据,取值范围为【10~100】
- 自定义测试数据集:可以通过上传测试数据集
资源配置
资源配置是用户在创建训练或推理任务时,为任务分配计算资源的关键设置环节。通过合理配置资源,可以确保任务高效执行并优化资源利用率。
主要配置项:
- 算力单元:通过滑动条直观调整整体算力配置
- 资源分配明细: • 显存(G):分配给任务的 GPU 显存大小 • GPU(个):分配的 GPU 数量 • 内存(G):分配的系统内存大小 • CPU(个):分配的 CPU 核心数
配额管理:
- 系统显示用户的总 GPU 配额、已使用配额及剩余配额
- 实时更新配额使用情况,确保用户了解资源限制
分配时可以参考【资源参考】,详情请见:训练&推理算力资源分配参考
注意:分配显存过少会导致任务失败
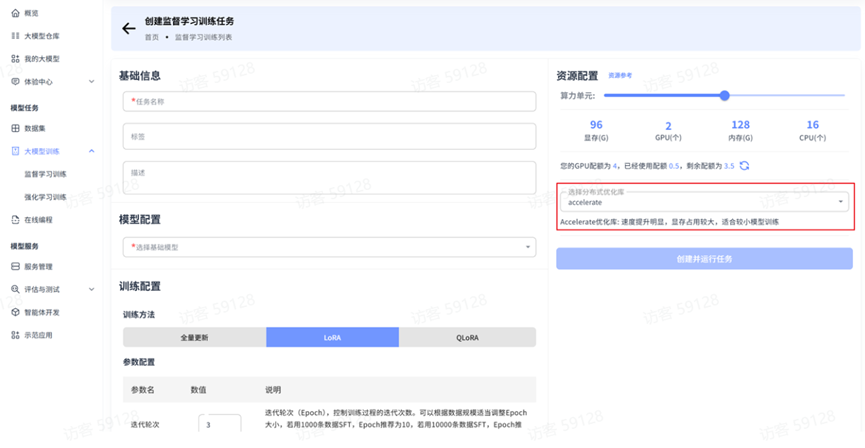
多卡训练分布式优化库
选择多卡训练时能够选择不同的分布式优化库优化训练。
平台提供两种分布式优化库:
Accelerate 优化库 Accelerate 是 Hugging Face 开发的简单而强大的分布式训练库,旨在简化深度学习模型在不同硬件设置下的训练过程。
优势:
- 支持多种训练模式,与 Hugging Face 生态系统完美集成
- 兼容各种训练框架(PyTorch、TensorFlow 等)
- 可与其他库(如 Transformers)无缝集成
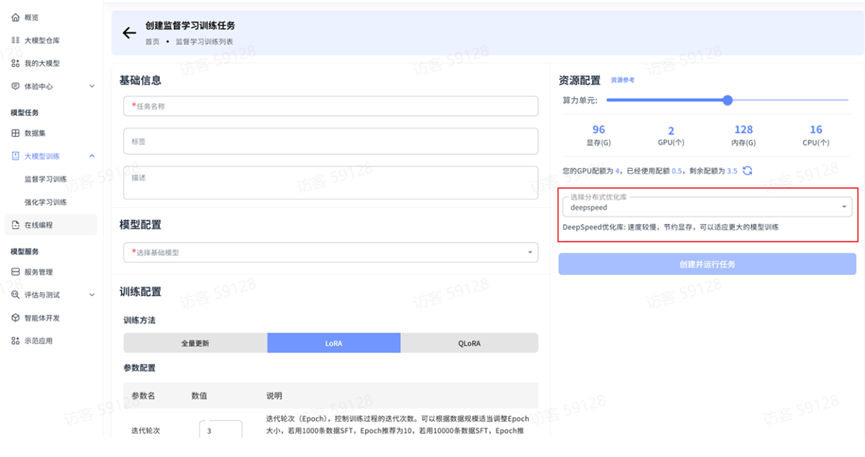
DeepSpeed 优化库 DeepSpeed 是微软开发的深度学习优化库,专注于大规模模型训练的极致优化,提供了全面的分布式训练解决方案。
优势:
- 极致的内存优化,支持超大模型训练
- 完整的并行训练方案
- 丰富的优化策略选择
- 训练效率高,尤其适合大规模模型
- 支持异构计算资源利用
对比总结
| 特性 | Accelerate | DeepSpeed |
|---|---|---|
| 使用门槛 | 低,适合快速上手 | 高,需要了解分布式训练原理 |
| 显存效率 | 一般 | 高(支持 ZeRO 优化) |
| 训练性能 | 适中 | 出色 |
| 适用规模 | 中小规模模型训练 | 大规模模型训练 |
| 扩展性 | 有限 | 强,支持多种并行策略 |
| 平台集成 | 完善,开箱即用 | 完善,开箱即用 |
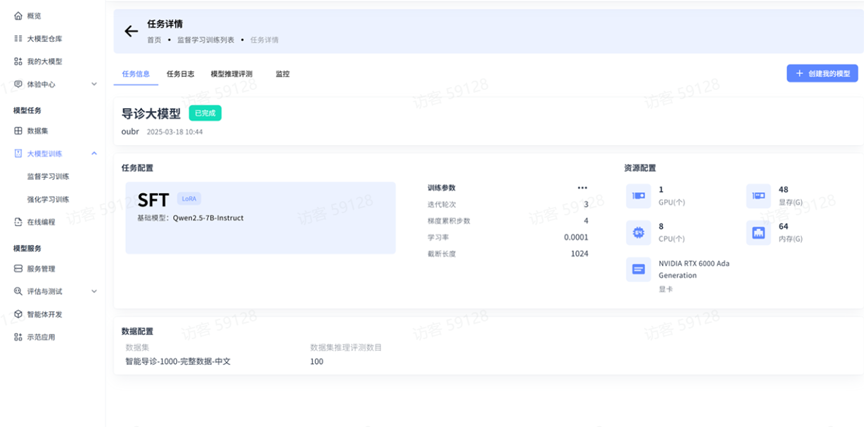
任务详情
训练过程中可以查看任务的具体信息:
任务信息:查看任务的状态、任务配置、数据配置、资源配置
任务日志:查看训练过程中的运行日志、训练日志、训练结果
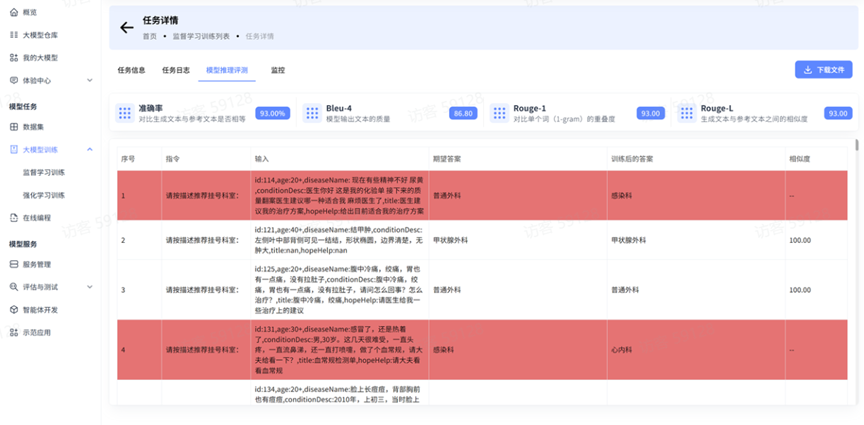
模型推理评测:查看推理验证结果,例如准确率、Bleu-4、Rouge-1、Rouge-L
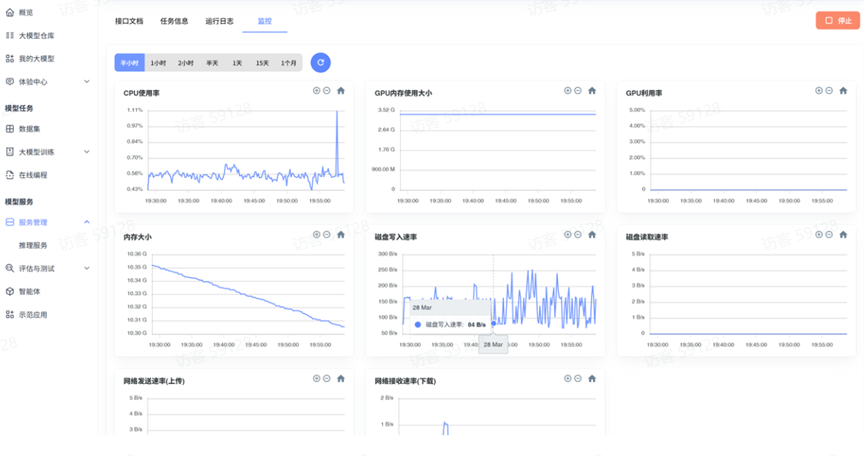
监控:查看 CPU 使用率、CPU 内存使用大小、GPU 利用率、内存大小、磁盘写入速率、磁盘读取速率等
强化学习训练(Reinforcement Learning from Human Feedback, RLHF)
RLHF 是一种通过人类反馈来优化模型输出质量的训练方法,能够使模型更好地理解和执行人类偏好,生成更符合人类期望的回答。
该训练方式通过奖励模型(Reward Model)引导模型学习,使其输出更符合人类价值观和偏好。
适用场景
- 对话系统优化(减少有害、不实或低质量回复)
- 复杂指令理解与执行
- 需要符合特定价值观或伦理标准的应用场景
- 需要更好的对齐人类偏好的任务
特点
- 需要人类反馈数据(偏好排序或评分)
- 训练过程分为奖励模型训练和策略优化两个阶段
- 能够显著提升模型输出的实用性、安全性和人类对齐度
- 相比 SFT,能更好处理开放式、多样化的任务
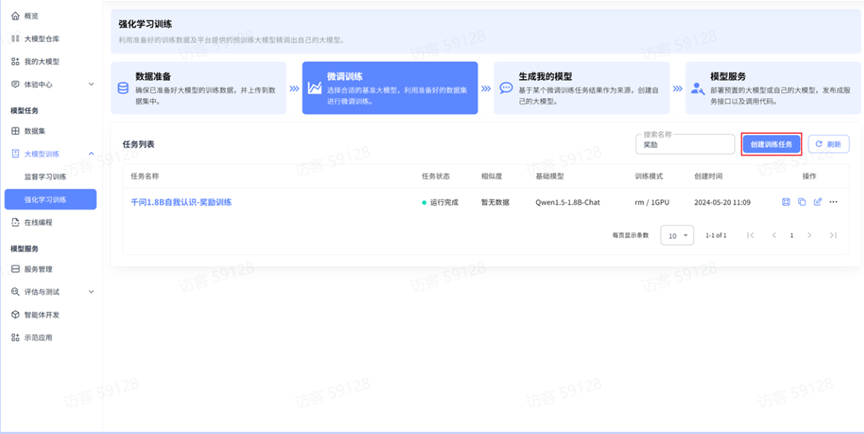
创建任务
如果您在训练任务列表已经有创建好的训练任务,可以直接点击【复制任务】创建相同参数的训练任务。
也可以点击【创建训练任务】直接创建新任务。
基本信息配置
填写好任务名称后,可以选择填写相应标签、描述等信息。
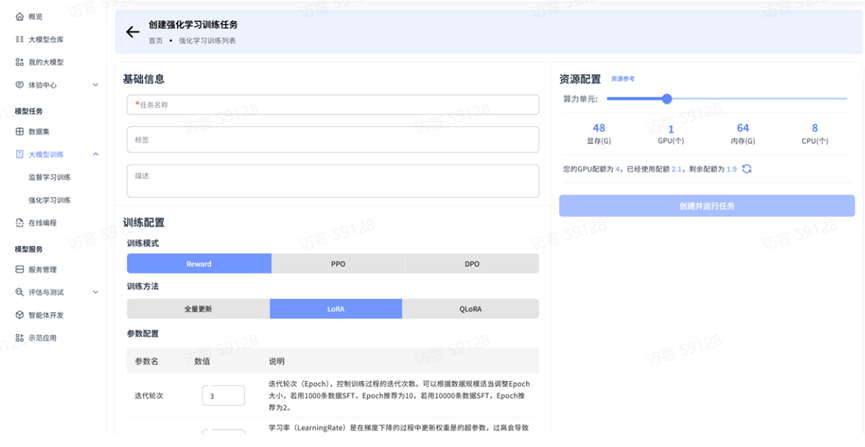
训练配置
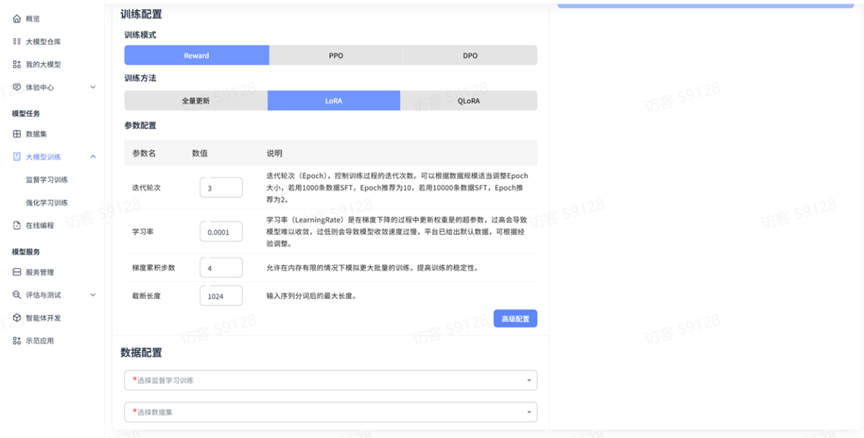
平台强化学习训练提供三种训练模式,分别是:reward、PPO、DPO,以及三种训练方法,分别是:全量更新、LoRA、QLoRA,用户可根据自身需求和资源条件选择最适合的方法。
训练模式对比
| 训练模式 | 原理 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| Reward | 通过环境奖励信号指导智能体学习最优策略 | • 直观易理解 • 可灵活调整任务目标 • 可通过奖励塑造加速学习 | • 奖励函数设计困难 • 奖励信号稀疏 • 存在奖励黑客问题 | 任务目标明确的场景,如机器人控制 |
| PPO | 通过限制策略更新步长确保学习稳定性 | • 实现简单计算效率高 • 防止策略更新过大 • 在线学习表现良好 | • 参数设置影响性能 • 某些情况下不如 TRPO 高效 | 需要稳定策略学习的场景 |
| DPO | 直接利用人类偏好数据优化策略 | • 直接利用人类偏好 • 捕捉细微偏好 • 适用于个性化任务 | • 需要大量偏好数据 • 数据质量影响效果 | 个性化推荐、对话系统等 |
训练方法
训练方法可参考监督学习训练中针对训练方法的描述:训练方法
参数配置
参数配置可参考监督学习训练中针对参数配置的描述:参数配置
数据配置
强化学习训练的数据配置与监督学习训练有所不同:
不同模式的数据依赖:
奖励模式(Reward Mode):需要已训练的监督学习模型作为起点
DPO 模式(Direct Preference Optimization):直接利用人类偏好数据,同样依赖监督学习模型
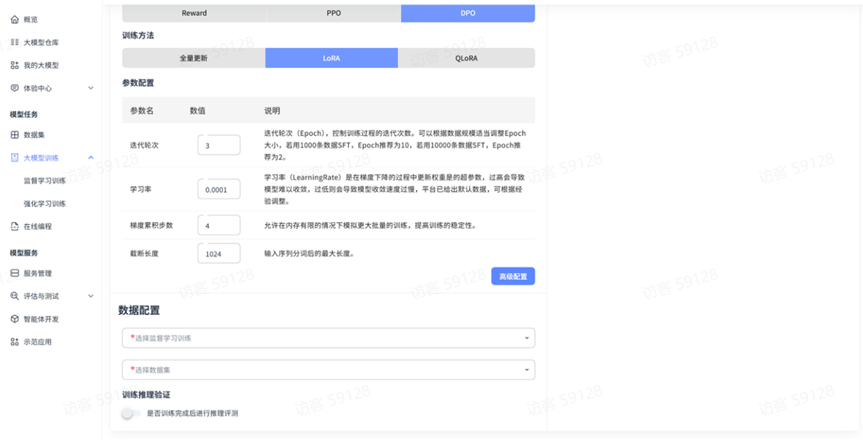
PPO 模式(Proximal Policy Optimization):需要监督学习训练模型和奖励训练模型
总结:
- 奖励模式和 DPO 模式都依赖于已训练的监督学习模型作为起点
- PPO 模式不仅需要监督学习模型,还需要专门的奖励模型提供学习信号
- 这些基础模型为强化学习智能体提供了初始知识和行为框架
数据集选择:用户可从个人或共享数据集中选择适合当前训练任务的数据集。
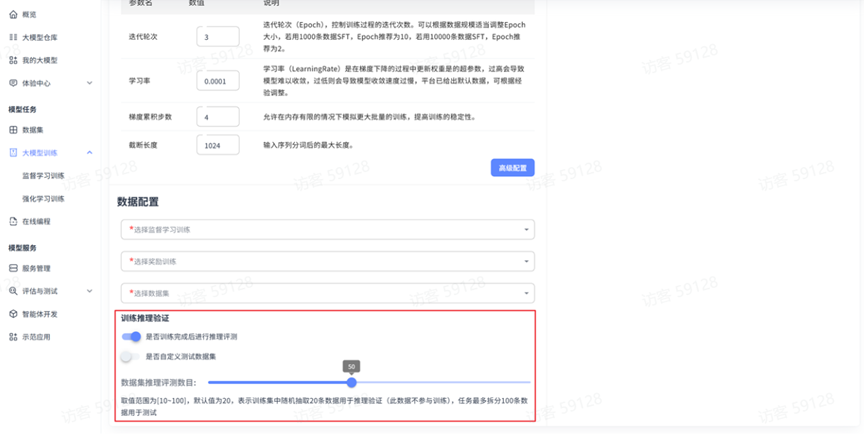
训练推理验证:
- 启用验证:可选择是否在训练过程中进行实时验证评估
- 评测指标:可选择多种评估指标
- 验证数据量:默认不抽取超过数据集数量一半的数据,取值范围为【10~100】
资源配置
资源配置可参考监督学习训练中针对资源配置的描述:资源配置
任务详情
任务详情可参考监督学习训练中针对任务详情的描述:任务详情